Articles

Frames Per Second (Part 3): Turning a Tiny Diffusion Model into a Traveling Photobooth
A tiny diffusion model, a mobile device, and a surprising amount of magic — here’s how I built a pocket-sized photobooth that can whisk real people into new worlds in under 30 seconds.
Frames Per Second (Part 2): Quantization, Kernels, and the Path to On-Device Diffusion
This post unpacks how quantization, ANE-optimized kernels, and smart schedulers shrink a 6GB diffusion model into a fast, mobile-ready package.

Frames Per Second (Part 1): The Hunt for a Tiny, High-Quality Diffusion Model
How I chased a diffusion model small enough for the iPhone, fast enough for real use, and resilient enough to avoid corruption—unpacking what works, what doesn’t, and why.
Decoding Transformers: A Concise Guide to Modern ML Research
For the past two months, I’ve been intensely studying the state-of-the-art in LLM research. This guide distills my findings into a practical resource for understanding the latest AI research.
Shrinking the Impossible (Part 4): Deploying My Own Pocket-Sized Multi-Modal Large Language Model
After painstakingly embedding a mini multi-modal LLaVA model, I’m ready to properly deploy it as an iOS app and enjoy the fruits of my labor. Let’s see if we can truly shrink the impossible.

Shrinking the Impossible (Part 3): Embedding a Custom-Defined LLaVA-OneVision Model with MLC
Armed with some newfound vision transformer knowledge, we’re ready to extend the Machine Learning Compiler framework to support a new, tiny but promising multi-modal model.

Shrinking the Impossible (Part 2): Teaching Chatbots to See with LLaVA, CLIP, and SigLIP
Vision transformers, with help from training frameworks like CLIP and SigLIP, make multi-modal foundation models like LLaVA possible — bridging the gap between vision and text.

Shrinking the Impossible (Part 1): Optimizing Foundation Models for Edge Devices with MLC
The open-source Machine Learning Compiler Engine project is transforming foundation models into efficient and portable powerhouses.
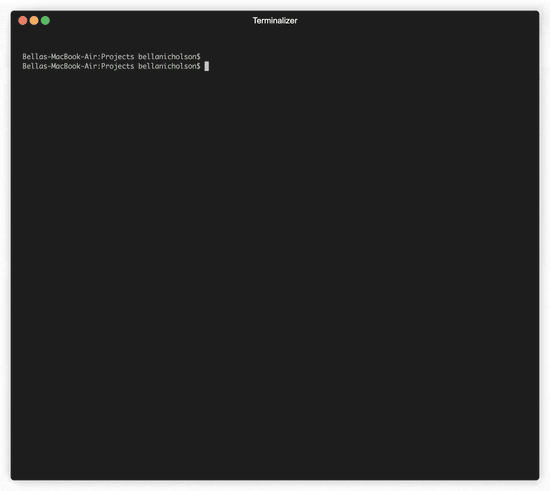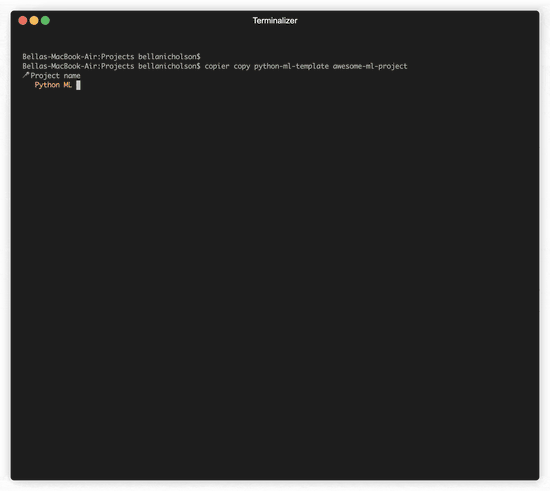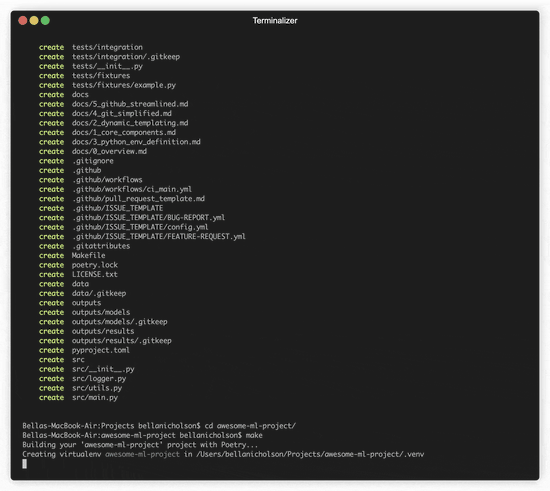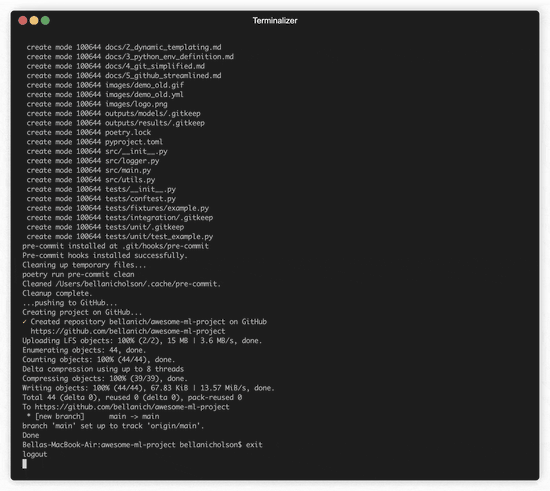
From Framework to Functionality: 📢 My Custom Python ML Template Launch
After churning out too many projects from scratch in one month, I built this ML template to make life easier—for both of us. Start ML development with just 3 commands.
Notes Alert: 📓 A Handy 3-Page Cheatsheet for Version Control Pros
As I transition to my new role, I used my downtime to go deep into Git — a tool I rely on daily — and condensed everything I learned into a concise, 3-page cheatsheet.

Reinforcement Learning: Investigating Gradient Stability in Policy Based Methods
How does the gradient stability differ between REINFORCE, G(PO)MDP, G(PO)MDP+ whitening during policy learning?
News
Frames Per Second (Part 3): Turning a Tiny Diffusion Model into a Traveling Photobooth
A tiny diffusion model, a mobile device, and a surprising amount of magic — here’s how I built a pocket-sized photobooth that can whisk real people into new worlds in under 30 seconds.
Frames Per Second (Part 2): Quantization, Kernels, and the Path to On-Device Diffusion
This post unpacks how quantization, ANE-optimized kernels, and smart schedulers shrink a 6GB diffusion model into a fast, mobile-ready package.
Frames Per Second (Part 1): The Hunt for a Tiny, High-Quality Diffusion Model
How I chased a diffusion model small enough for the iPhone, fast enough for real use, and resilient enough to avoid corruption—unpacking what works, what doesn’t, and why.
Decoding Transformers: A Concise Guide to Modern ML Research
For the past two months, I’ve been intensely studying the state-of-the-art in LLM research. This guide distills my findings into a practical resource for understanding the latest AI research.
Shrinking the Impossible (Part 4): Deploying My Own Pocket-Sized Multi-Modal Large Language Model
After painstakingly embedding a mini multi-modal LLaVA model, I’m ready to properly deploy it as an iOS app and enjoy the fruits of my labor. Let’s see if we can truly shrink the impossible.
Shrinking the Impossible (Part 3): Embedding a Custom-Defined LLaVA-OneVision Model with MLC
Armed with some newfound vision transformer knowledge, we’re ready to extend the Machine Learning Compiler framework to support a new, tiny but promising multi-modal model.
Shrinking the Impossible (Part 2): Teaching Chatbots to See with LLaVA, CLIP, and SigLIP
Vision transformers, with help from training frameworks like CLIP and SigLIP, make multi-modal foundation models like LLaVA possible — bridging the gap between vision and text.
Shrinking the Impossible (Part 1): Optimizing Foundation Models for Edge Devices with MLC
The open-source Machine Learning Compiler Engine project is transforming foundation models into efficient and portable powerhouses.
From Framework to Functionality: 📢 My Custom Python ML Template Launch
After churning out too many projects from scratch in one month, I built this ML template to make life easier—for both of us. Start ML development with just 3 commands.
Notes Alert: 📓 A Handy 3-Page Cheatsheet for Version Control Pros
As I transition to my new role, I used my downtime to go deep into Git — a tool I rely on daily — and condensed everything I learned into a concise, 3-page cheatsheet.
Reinforcement Learning: Investigating Gradient Stability in Policy Based Methods
How does the gradient stability differ between REINFORCE, G(PO)MDP, G(PO)MDP+ whitening during policy learning?