Shrinking the Impossible (Part 4): Deploying My Own Pocket-Sized Multi-Modal Large Language Model
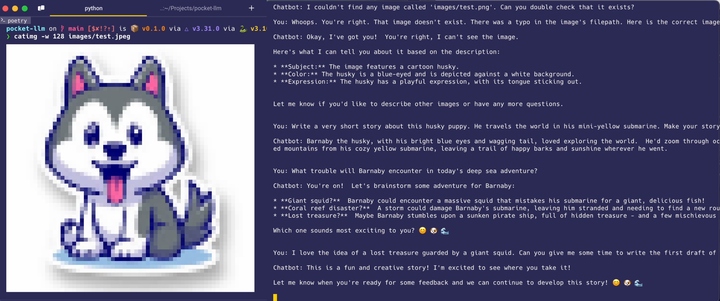 Image: My Embedded Multi-Modal Model
Image: My Embedded Multi-Modal ModelTable of Contents
Introduction
If you’ve been following along in this blog post series, you know that I got a little too inspired at this year’s Google I/O Connect event. After hearing about Google’s incredible feat of embedding Gemini Nano into their Pixel 8 phones, I’ve been not-so-patiently waiting for the open source community to release tools that make similar feats possible for solo developers like me. Fortunately, the Machine Learning Compiler (MLC) project has matured enough that my dreams might just be possible.
Hence, I’ve been a personal quest to assess the limits of this new and exciting technology. To keep things interesting, I’ve decided to embed a multi-modal LLM. I want to test a less established setup, but I’m also secretly hoping to have a nice souvenir after everything is said and done. (Personally, I could really use a multi-lingual and multi-modal chatbot during my next holidays — especially once that doesn’t eat up my monthly data plan.)
At this point, I’m very close to this end goal. In my first blog post in this series, I introduced you to the MLC framework, which has been doing most of the heavy-lifting. I also gave you a quick crash course in what it takes to embed a large machine learning model on a resource-constrained device. In the 2nd blogpost, I gave you a primer on vision transformers — specifically, what we need to know to embed this tiny and multi-modal LLaVA-OneVision Qwen2 0.5B model. In my last blog post, I used this LLaVA model as an example to show you how to extend the MLC framework to support a custom model definition.
After going through this entire process, I have a fully functional - but not very logical - LLaVA model running on my laptop. As the name suggests, this LLaVA model belongs to the high-performing, open source, and multi-modal Large Language and Vision Assistant (LLaVA) model family. Fortunately, for us, this model has less than 0.5B parameters. Meaning, it should be small enough to squeeze onto an iPhone. Here’s what its chat conversations look like:


Given this LLaVA model’s lack of coherence, we don’t want it talking directly to our end user. Rather, we’ll let it stick to what it does best (image annotation) and call in a slightly large LLM for backup.
My Game Plan
So, what’s next? If you recall the diagram that I shared with you in the last time, I need to deploy a two-model ensemble. My plan is to use LLaVa-OneVision’s image annotation capabilities to expand Gemma 2B’s ridiculously good conversational capabilities. Essentially, LLaVA will describe the user provided image to Gemma in plain text. Gemma will receive the original user prompt and LLaVA’s image description. Between these two, Gemma should have enough information to return a lucid and logical response.

Deployment
My original vision was to have an edge multi-modal embedded onto my iPhone. That way, I could chat with my personal travel assistant anytime and anywhere — no internet connection required.
Attempt 1: Deploying my multi-modal model as an iOS app
Before I can package Gemma 2B and LLaVA together as a single model, I first need to figure out how to input images into MLC’s simple, pre-built chat iOS application, and this is where I run into my first roadblock.
If you’re observant, you might have noticed the grayed out text “Upload picture to chat” in my conversation screenshots with LLaVA. One could logically conclude that this means that MLC has some sort of user interface for uploading images. However, after pouring over the Swift code, I couldn’t find any such feature. Before I start cobbling something together in Swift, I decide to do a quick sanity check: Can I pass an image URL to the MLC Chat Engine?
Well…not really. I’d have to go in deep to the MLC’s low code and Swift implementations to make that possible. That’s a rabbit hole that I don’t want to fall into, so it’s time for me to pivot directions.
What if the MLC Chat Engine supported uploading images?
Let’s suppose that I was able to the the MLC Chat Engine iOS implementation so that it:
- It now supports serving images to models.
- There’s a cool and sleek user interface for uploading said images.
Could I deploy any of the Apple products in my household? Well, I decided to do an initial test on my housemate’s iPad Pro 11 inch (V1). I copied over and downloaded my iOS app. While I was able to open the app’s homepage and start my conversation with Gemma 2B, the app would crash before I could even ask Gemma a followup question.
Perplexed, I checked my iOS app’s memory consumption in Xcode after I opened a new chat with Gemma. Well, it turns out that Gemma consumes a bit over 2GB of RAM. Given that this borrowed iPad only has 4GB of RAM in total, it’s not a surprise that the iOS application was crashing. Even when I closed all other applications, other background processes were consuming this iPad’s limited and valuable memory.


In contrast, the LLaVA-OneVision model has a much smaller memory footprint at 755MB. So, yes, it’s technically possible to deploy only the LLaVA-OneVision model on this given iPad; however, it’s probably not worth it. As we’ve seen from this blog post’s introduction, the embedded LLaVA-OneVision model isn’t capable of holding a coherent conversation for very long. Meaning, Gemma’s memory consumption is a definitive roadblock in my app ambitions.
As a final check, I tried the same exercise with my iPhone 13 and got similar results. This is expected, given that both devices have the same memory capacity. Of course, all the Apple devices I could find are on the older side. Apple’s newer iPhones and iPads have a large enough RAM that I should be able to deploy Gemma 2B and LLaVA-OneVision Qwen2 0.5B together.
| Device | Available RAM |
|---|---|
| iPhone X | 3GB |
| iPhone 13 | 4G |
| iPad Pro V1 | 4G |
| iPhone 16 | 8G |
| iPad Air 6 | 8G |
The available RAM on Apple’s latest iPhone and iPad models is a testament to its commitment to cram AI tools and features into every part of the Apple user experience. Of course, it’s also wild to think that the latest iPhone is just as computationally strong — at least in RAM — as my laptop. This also means that if I could feed images into the iOS MLC Chat Engine, then I should be able to very easily deploy my multi-modal model setup on an iPhone — just not my phone.
That being said, I’m not in a rush to get the latest iPhone. I just have something to look forward to when its inevitably time to replace my current one.
Changing Directions
At this point, I’ve ruled out the possibility of deploying my multi-modal foundation model on any Apple device, especially those within my immediate reach.
Now, I’m trying to contend with two different mysteries:
- Why does MLC natively support some LLaVA models, but doesn’t support serving images? The main added value of the LLaVA model family is their exceptional ability to handle multi-modal inputs.
- Does the MLC Engine support serving a model images in any other platform-specific chat engine implementation?
Realistically, I don’t think that I’m going to get an answer to my first question unless I manage to chase down some of the MLC project’s main contributors. Fortunately, the second question is easier to answer. If you recall from my first blog post, MLC implements their own version of OpenAI’s Python API.
Since the original Python API supports serving images, there’s a good chance that the MLC implementation might offer the same functionality.

Sure enough, I look through when I look through the mlc-llm-cpu library’s source code, I find the same image_url variable in their conversation protocol definition.
class Conversation(BaseModel):
...
def as_prompt(self, config=None) -> List[Any]:
...
for item in content:
assert isinstance(item, dict), "Content should be a string or a list of dicts"
assert "type" in item, "Content item should have a type field"
if item["type"] == "text":
message = self.role_templates[role].replace(
MessagePlaceholders[role.upper()].value, item["text"]
)
message_list.append(message)
# MLC supports passing image URLs via its Python API
elif item["type"] == "image_url":
assert config is not None, "Model config is required"
image_url = _get_url_from_item(item)
message_list.append(data.ImageData.from_url(image_url, config))
message_list.append("\n")
else:
raise ValueError(f"Unsupported content type: {item['type']}")
message_list.append(separator)
...
return prompt
Meaning, I still can implement my multi-modal chat pipeline via a Python script.
Attempt 2: Deploying my multi-modal model as a Python CLI
At this point, I just want to see if I could successfully deploy the embedded multi-modal foundation model on some device that I own. So, I wrote a very simple Python script that lets a user interact with my chat pipeline via the commandline. If the user provides an image filepath, the model will check if it’s there. If so, underneath the hood, LLaVA is annotating this image for Gemma 2B. If not, my chatbot will kindly ask the user to check if the image is really there. Otherwise, Gemma 2B will be doing all the talking.
Here’s the end result:

As you can see, the LLaVA model was able to recognize the Husky in the cartoon image and pass this information along to Gemma. Afterwards, Gemma was able to quickly help me draft an initial synopsis for about a day in the life of Barnaby, a sea-faring Husky who travels the world in his tiny yellow submarine. If we had a bit more compute power and a stronger LLaVA model, perhaps we could also extend this system to support image generation. If so, do think you “Barnaby’s Deep Sea Adventures” could become an international bestseller?
For the exact source code used in this demo, please refer to this blog post’s corresponding GitHub repository.
Conclusion
It’s truly incredible seeing how quickly embedded systems technology has progressed in this domain. The tech giants are definitely in a comfortable place when it comes to deploying sophisticated edge foundation models, but the open source tooling is still in its early phase. Through this project, I’ve defined stumbled over a few vague, low-level code errors of my own. Tools like the MLC framework (in their current iteration) well-suited for those of us who are:
- Well-versed in the latest deep learning research
- Comfortable debugging low code system errors
- Reasonably proficient in Swift (or similar programming languages)
- Own latest edge devices
Of course, that’s a lot of conditions. Nonetheless, it’s incredible seeing how projects like the Machine Learning Compiler have democratized access to foundation models. Whether you’re moonlighting as an entrepreneurial or are a curious university student, you can get easily started deploying your own single-modal LLMs on edge today. Maybe in another 6 months, the tooling will have advanced to the point that it fully supports multi-modal chat — including image generation.
In the meantime, I plan to watch these industry development closely. While I’ve put my hopes of a private, multi-modal travel assistant on the shelf, I haven’t abandoned them entirely. Stay tuned to see what I’ll do next. 👋