Decoding Transformers: A Concise Guide to Modern ML Research
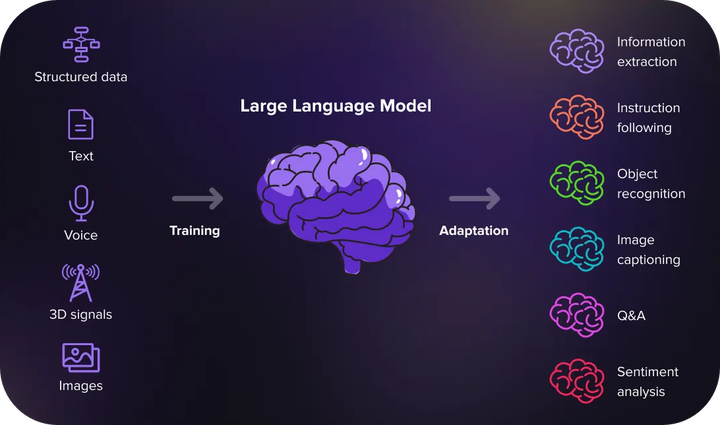 Image from SoluLab
Image from SoluLabI’ve had a whirlwind introduction to world of LLMs. Between my adventure in embedding a multi-modal foundation model on various iOS devices and jetting of to NeurIPS 2024 in Vancouver 🇨🇦, I’ve been immersed in all things related to LLMs.

I’ve spent countless hours talking to the researchers building state-of-the-art LLMs and even more time pouring over online resources to understand the fundamentals. To save you the trouble, I’ve organized everything I’ve learned into a handy study guide: “Transformers Decoded: A Quick Guide to ML Research” .
This guide explains key concepts, industry trends, and the critical optimization techniques that make LLMs so performant. We pay close attention to crucial inference optimization techniques, including:
- Speculative decoding: Inference is accelerated by generating multiple candidate outputs with a smaller LLM and verifying them with a larger, more accurate LLM.
- Flash attention: By restructuring the attention operations to minimize memory reads and writes — the bottleneck in classical attention — we achieve significant speedups.
- Continuous batching: Incoming requests are dynamically batched to maximize hardware utilization and throughput, especially in online serving.
Further details on these (and other) optimization techniques can be found the PDF below. Let’s decode the latest in AI research, together!